3087 words, 9 mins
linux 性能优化学习第六周总结,本周还是 网络性能优化
本周读完了最后一部分网络性能优化章节,跟着作者整理的脉络,在整体上对网络性能该如何排查有了不错的理解。
总体而言:
- 在应用程序中,主要是优化 I/O 模型、工作模型以及应用层的网络协议;
- 在套接字层中,主要是优化套接字的缓冲区大小;
- 在传输层中,主要是优化 TCP 和 UDP 协议;
- 在网络层中,主要是优化路由、转发、分片以及 ICMP 协议;
- 最后,在链路层中,主要是优化网络包的收发、网络功能卸载以及网卡选项。
- 使用 DPDK 等用户态方式,绕过内核协议栈;或者,使用 XDP,在网络包进入内核协议栈前进行处理。
确定优化目标
网络性能优化的整体目标是:降低网络延迟(如 RTT)和提高吞吐量(如BPS 和 PPS),而针对不同应用场景侧重点不同。
- NAT网关,主要针对 PPS 作为性能目标
- 对于数据库,缓存,主要是快速完成网络收发,降低延迟
- Web 服务,需要同时兼顾吞吐量和延迟
基准测试
根据网络协议栈,可以对每一层进行测试
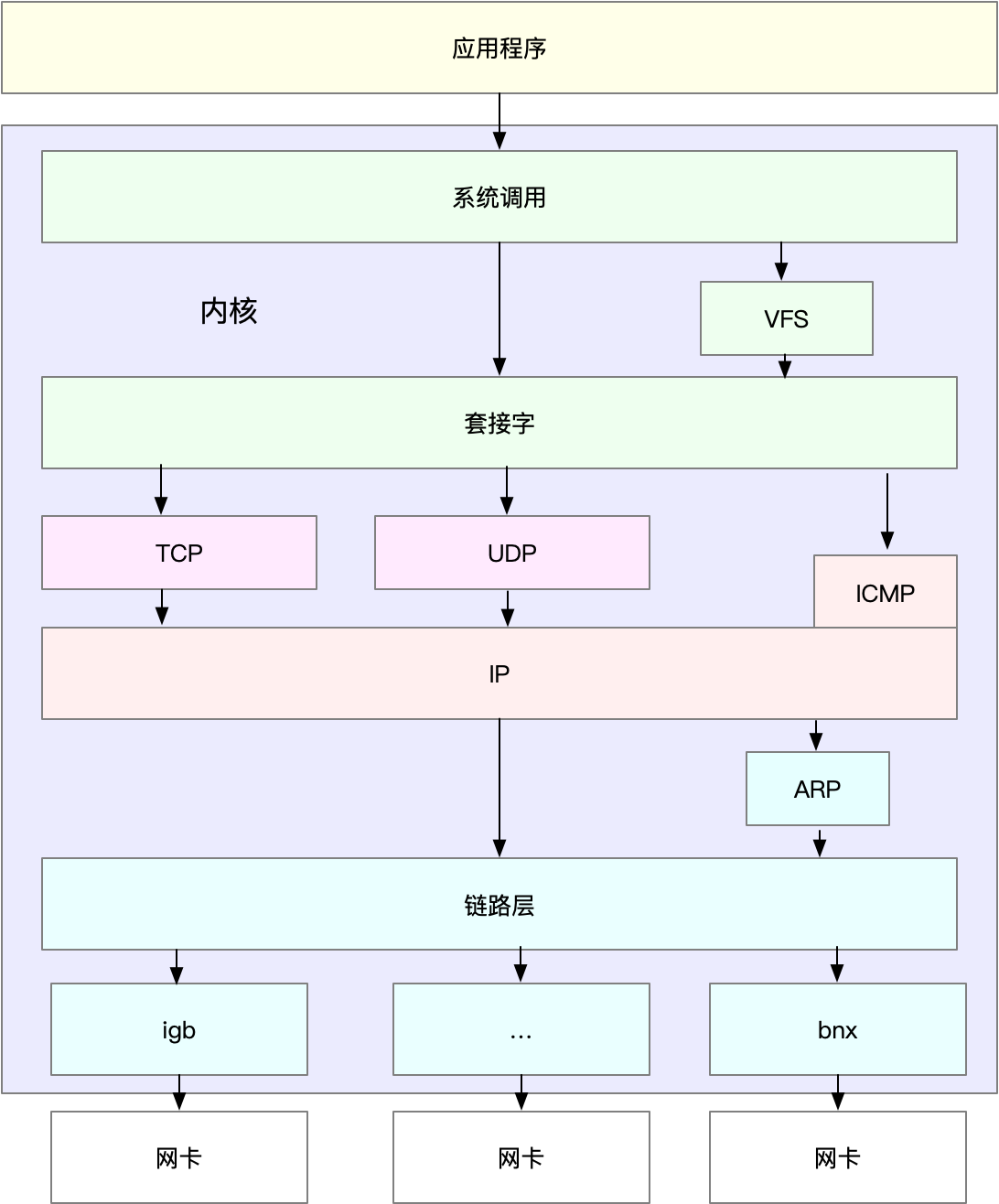
可以从下到上先进行测试:
- 网络层主要负责网络包的封装、寻址、路由,以及发送和接收,主要关心每秒可处理的网络包数 PPS,可以用内核自带的发包工具 pktgen ,来测试 PPS 的性能。
- 传输层TCP,UDP,主要负责网络传输。主要关心吞吐量(BPS)、连接数以及延迟,可以用 iperf 或 netperf ,来测试传输层的性能。注意不同网络包大小对性能的影响
- 应用层,最需要关注的是吞吐量(BPS)、每秒请求数以及延迟等指标。可以用 wrk、ab 等工具,来测试应用程序的性能。可以录制实际的请求数据,进行测试回放
网络性能优化
根据网络协议栈和网络收发流程,逐步优化
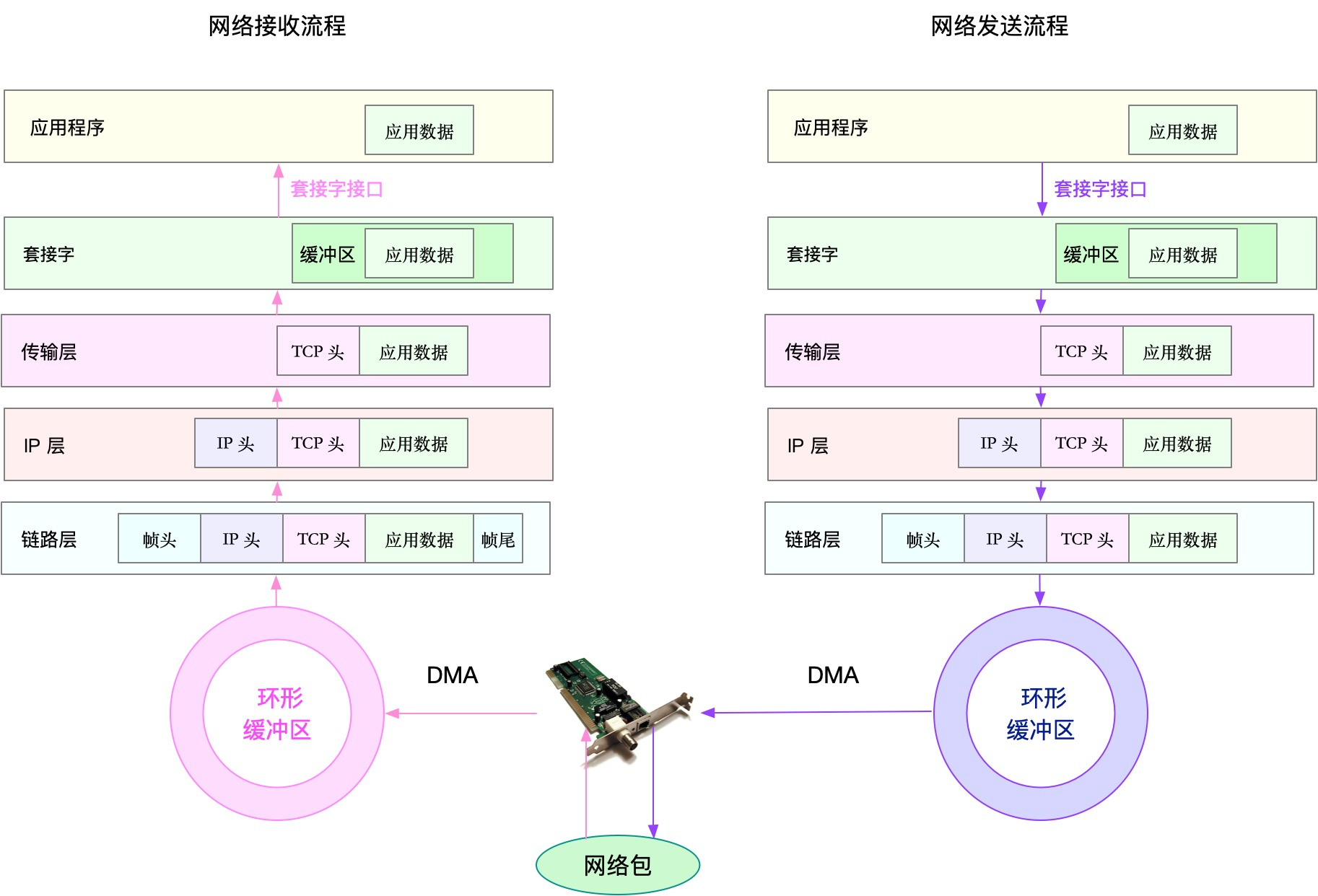
应用程序
IO模型优化
- 使用 I/O 多路复用技术epoll,解决 C10K 问题
- 或者使用异步 I/O(Asynchronous I/O,AIO),不过使用比较复杂,需要小心处理很多情况
进程模型优化
- 主进程+多子进程。主进程负责管理网络连接,子进程负责业务
- 多进程。所有进程监听相同端口,开启
SO_REUSEPORT选项,由内核来负载均衡
网络协议优化
- 使用长连接取代短连接
- 使用内存缓存不常变化的数据
- 使用 Proto Buffer等序列化方式,压缩网络 IO的数据量,来提高吞吐
- DNS 缓存、预取、HTTPDNS 等方式,减少 DNS 解析的延迟,也可以提升网络 I/O 的整体速度。
套接字
- 增大每个套接字的缓冲区大小 net.core.optmem_max;
- 增大套接字接收缓冲区大小 net.core.rmem_max 和发送缓冲区大小 net.core.wmem_max;
- 增大 TCP 接收缓冲区大小 net.ipv4.tcp_rmem 和发送缓冲区大小 net.ipv4.tcp_wmem。
参考设置
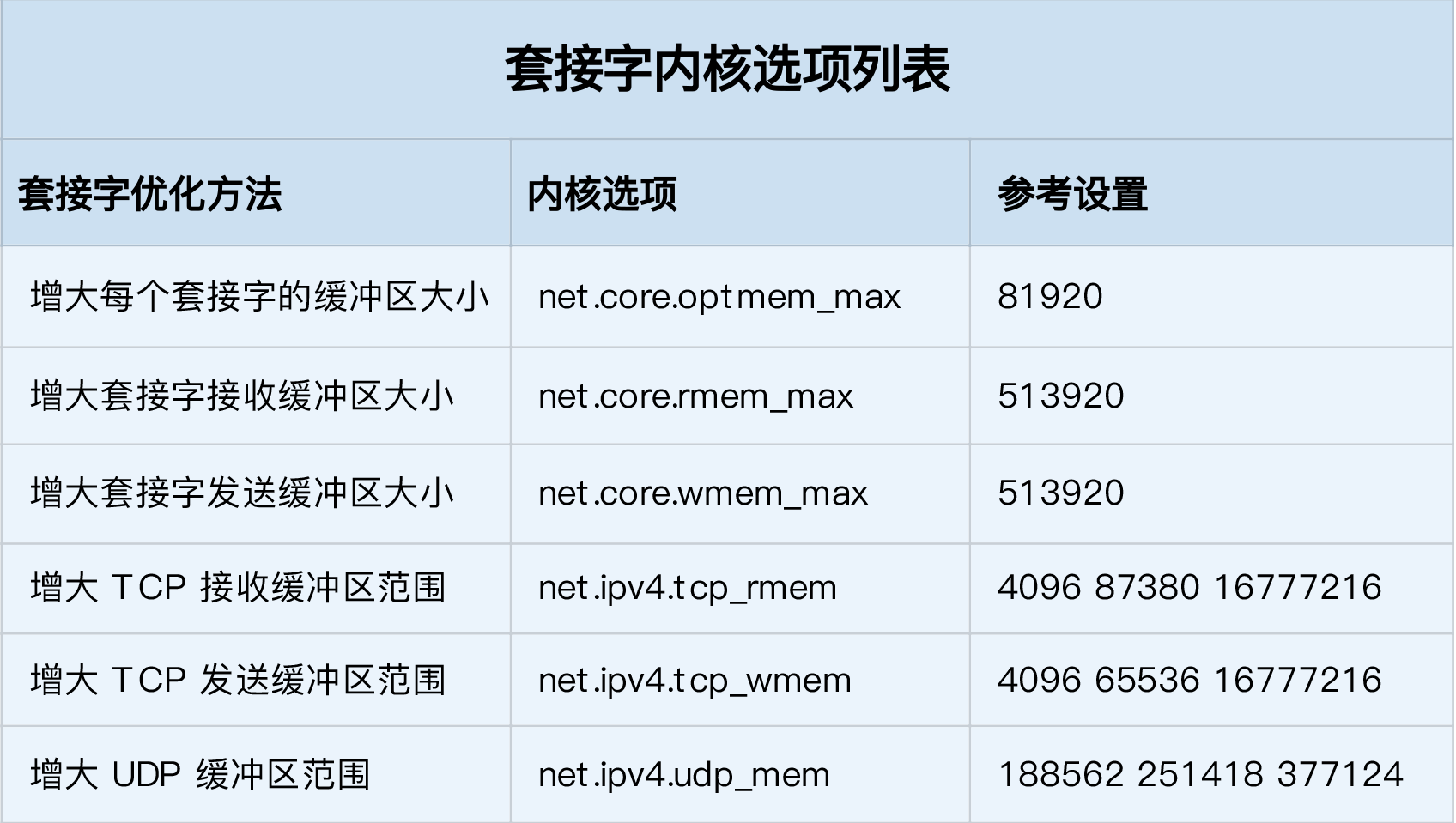
- tcp_rmem 和 tcp_wmem 的三个数值分别是 min,default,max,系统会根据这些设置,自动调整 TCP 接收 / 发送缓冲区的大小。
- udp_mem 的三个数值分别是 min,pressure,max,系统会根据这些设置,自动调整 UDP 发送缓冲区的大小。
其他配置选项:
- 为 TCP 连接设置 TCP_NODELAY 后,就可以禁用 Nagle 算法;
- 为 TCP 连接开启 TCP_CORK 后,可以让小包聚合成大包后再发送(注意会阻塞小包的发送);
- 使用 SO_SNDBUF 和 SO_RCVBUF ,可以分别调整套接字发送缓冲区和接收缓冲区的大小。
传输层
TCP
首先要掌握 TCP 协议的基本原理,比如流量控制、慢启动、拥塞避免、延迟确认以及状态流图。
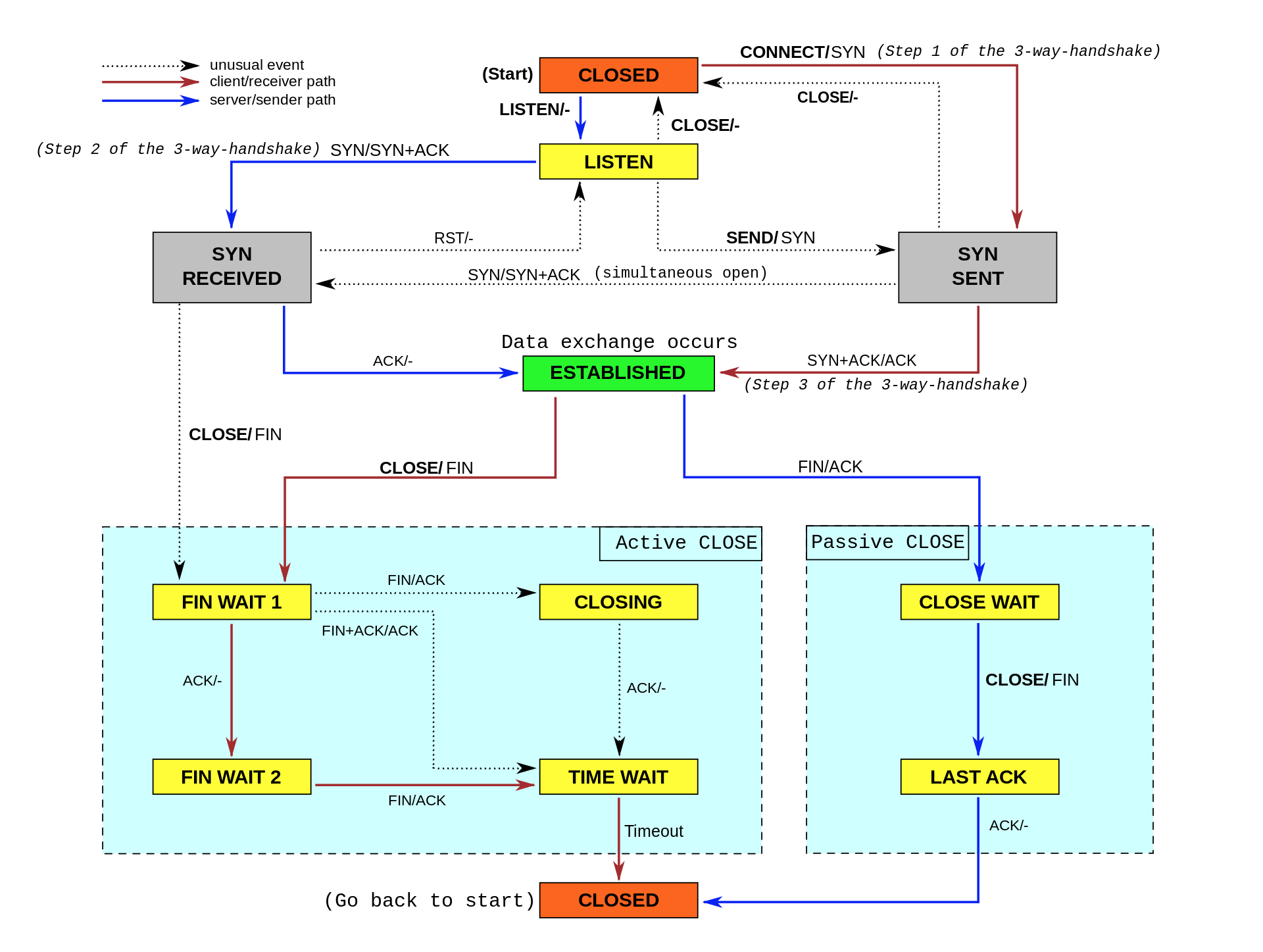
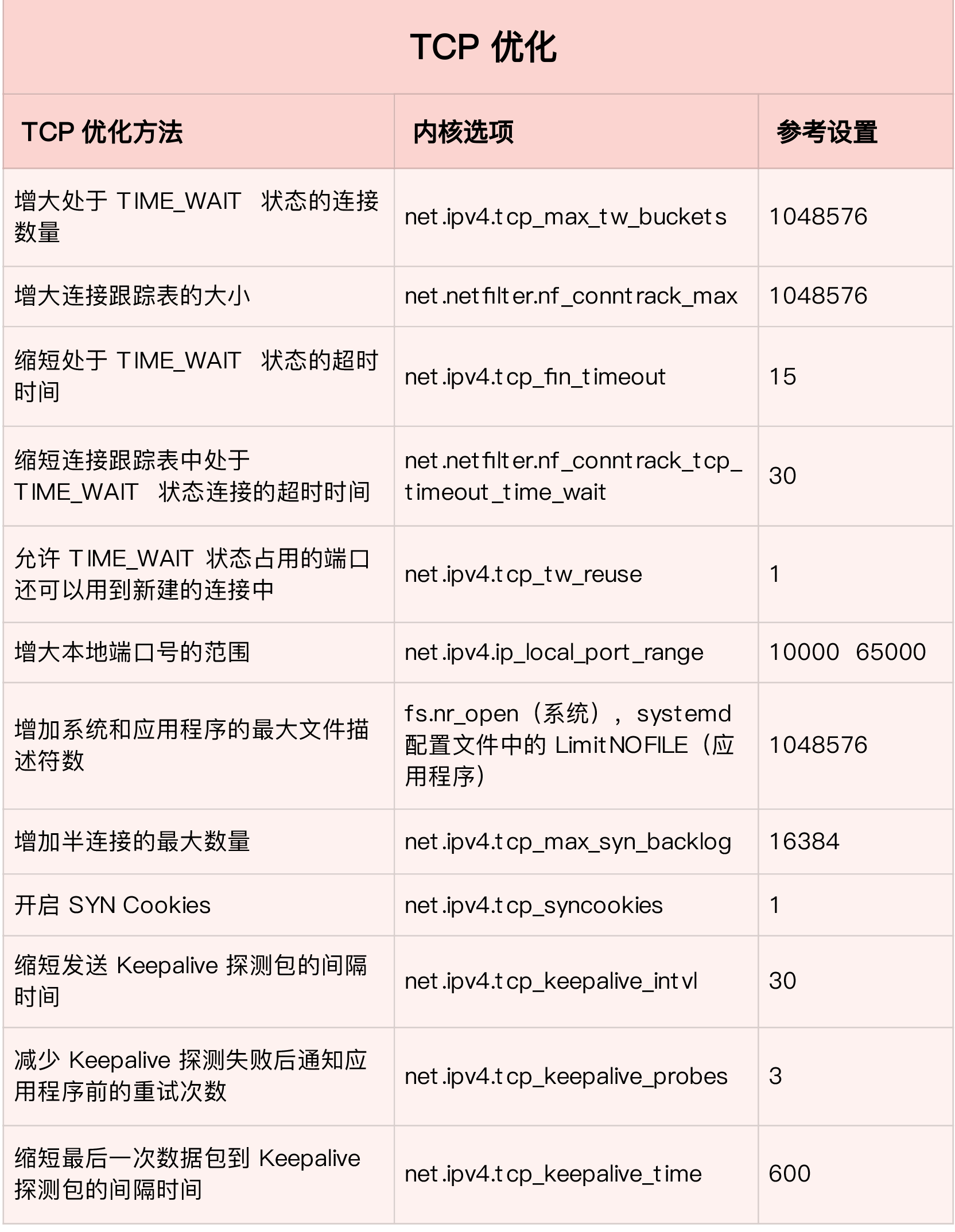
请求数比较大的时候,针对大量TIME_WAIT连接
- 增大处于 TIME_WAIT 状态的连接数量 net.ipv4.tcp_max_tw_buckets ,并增大连接跟踪表的大小 net.netfilter.nf_conntrack_max。
- 减小 net.ipv4.tcp_fin_timeout 和 net.netfilter.nf_conntrack_tcp_timeout_time_wait ,让系统尽快释放它们所占用的资源。
- 开启端口复用 net.ipv4.tcp_tw_reuse。这样,被 TIME_WAIT 状态占用的端口,还能用到新建的连接中。
- 增大本地端口的范围 net.ipv4.ip_local_port_range 。这样就可以支持更多连接,提高整体的并发能力。
- 增加最大文件描述符的数量。你可以使用 fs.nr_open 和 fs.file-max ,分别增大进程和系统的最大文件描述符数;或在应用程序的 systemd 配置文件中,配置 LimitNOFILE ,设置应用程序的最大文件描述符数。
减缓 SYN FLOOD 攻击
- 增大 TCP 半连接的最大数量 net.ipv4.tcp_max_syn_backlog ,或者开启 TCP SYN Cookies net.ipv4.tcp_syncookies ,来绕开半连接数量限制的问题(注意,这两个选项不可同时使用)。
- 减少 SYN_RECV 状态的连接重传 SYN+ACK 包的次数 net.ipv4.tcp_synack_retries。
长连接场景:
- 缩短最后一次数据包到 Keepalive 探测包的间隔时间 net.ipv4.tcp_keepalive_time;
- 缩短发送 Keepalive 探测包的间隔时间 net.ipv4.tcp_keepalive_intvl;
- 减少 Keepalive 探测失败后,一直到通知应用程序前的重试次数 net.ipv4.tcp_keepalive_probes。
推荐设置
UDP
- 增大套接字缓冲区大小以及 UDP 缓冲区范围;
- 跟前面 TCP 部分提到的一样,增大本地端口号的范围;
- 根据 MTU 大小,调整 UDP 数据包的大小,减少或者避免分片的发生。
网络层
网络层,负责网络包的封装、寻址和路由,包括 IP、ICMP 等常见协议。在网络层,最主要的优化,其实就是对路由、 IP 分片以及 ICMP 等进行调优。
路由和转发场景
- 在需要转发的服务器中,比如用作 NAT 网关的服务器或者使用 Docker 容器时,开启 IP 转发,即设置 net.ipv4.ip_forward = 1。
- 调整数据包的生存周期 TTL,比如设置 net.ipv4.ip_default_ttl = 64。注意,增大该值会降低系统性能。
- 开启数据包的反向地址校验,比如设置 net.ipv4.conf.eth0.rp_filter = 1。这样可以防止 IP 欺骗,并减少伪造 IP 带来的 DDoS 问题。
分片角度
- 通常,MTU 的大小应该根据以太网的标准来设置。以太网标准规定,一个网络帧最大为 1518B,那么去掉以太网头部的 18B 后,剩余的 1500 就是以太网 MTU 的大小。
限制 ICMP
- 比如,你可以禁止 ICMP 协议,即设置 net.ipv4.icmp_echo_ignore_all = 1。这样,外部主机就无法通过 ICMP 来探测主机。
- 或者,你还可以禁止广播 ICMP,即设置 net.ipv4.icmp_echo_ignore_broadcasts = 1。
链路层
由于网卡收包后调用的中断处理程序(特别是软中断),需要消耗大量的 CPU。所以,将这些中断处理程序调度到不同的 CPU 上执行,就可以显著提高网络吞吐量。
另外,现在的网卡都有很丰富的功能,原来在内核中通过软件处理的功能,可以卸载到网卡中,通过硬件来执行。
对于网络接口本身,也有很多方法,可以优化网络的吞吐量。
C10M极限场景
- 使用 DPDK 技术,跳过内核协议栈,直接由用户态进程用轮询的方式,来处理网络请求。同时,再结合大页、CPU 绑定、内存对齐、流水线并发等多种机制,优化网络包的处理效率。
- 使用内核自带的 XDP 技术,在网络包进入内核协议栈前,就对其进行处理,这样也可以实现很好的性能。
PREVIOUS第5周总结-网络
NEXT第7周总结-综合实战